Prometheus
Prometheus
架构
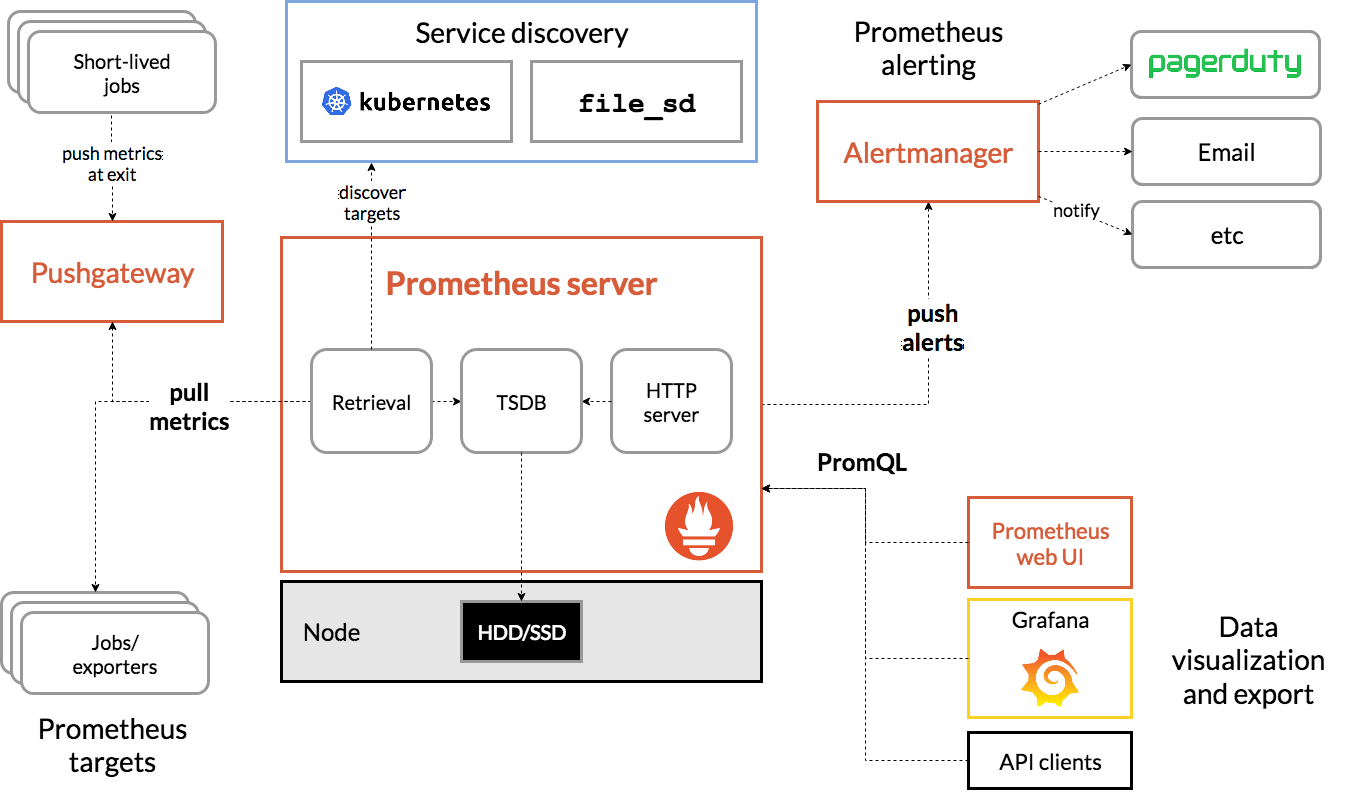
- Prometheus Server:用于抓取和存储时间序列化数据
- Exporters:主动拉取数据的插件
- Pushgateway:被动拉取数据的插件
- Altermanager:告警发送模块
- Prometheus web UI:界面化,也包含结合Grafana进行数据展示或告警发送
- 默认端口号为: 9090
Prometheus如何存储数据
TSDB存储原理: https://zhuanlan.zhihu.com/p/498612076
采用time-series(时间序列)方式,存储在本地硬盘
time-series数据库以每2小时间隔来分block(块)存储,每个块又分为多个chunk文件,chunk文件用来存放采集的数据的数据,metadata和索引文件;
index文件是对metrics和labels进行索引之后存储在chunk中,chunk是作为基本存储单位,index和metadata作为子集;
prometheus平时采集到的数据先存放在内存之中,对内存消耗大,以缓存的方式可以加快搜索和访问
在prometheus宕机时,prometheus有一种保护机制WAL,将数据定期存入硬盘中以chunk来表示,在重新启动时,可以恢复进内存当中。
当通过API删除序列时,删除的记录存储在单独的tombstone文件中(而不是立即从块文件中删除数据)
数据采集的方式
pull
- 被监控主机安装各类已有的exporters
- exporters以守护进程的模式运行,并开始采集数据
- exporters是http_server,可以对http请求作出响应,并返回K/V数据,也就是metrics
- prometheus通过用pull的方式(HTTP_GET)去访问每个节点上的exporter并采集回需要的数据
push
- 被监控主机安装官方的pushgateway插件
- 通过自行编写的各种脚本,将监控数据组织成K/V的形式(metrics形式)发送给pushgateway
- pushgateway再推送给prometheus
- pushgateway只是一个中间转发的媒介,可以被安装在任何地方
什么是metrics
- metrics是对采集过来的数据的一种统称
- 类型:
- Gauges: 最简单的度量指标,只有一个简单的返回值,或者叫做瞬时状态
- Counters: Counters就是计数器
- Histograms:柱状图,用于观察结果采样
- histograms 公开桶式观察计数,而histogram 的桶中的分位数计算在服务器端使用 histogram_quantile() 函数。每个配置的存储桶有一个时间序列。
- Summary:类似Histogram,用于表示一段时间内数据采样结果
- summaries 在客户端侧计算数据流的分位数并直接公开它们
什么是node-exporter
Prometheus为了支持各种中间件以及第三方的监控提供了exporter,监控适配器,将不同指标类型和格式的数据统一转化为Prometheus能够识别的指标类型。他们将这些异构的数据转化为标准的Prometheus格式,并提供HTTP查询接口。
默认监听9100端口
- Node exporter主要通过读取Linux的/proc以及/sys目录下的系统文件获取操作系统运行状态
- redis exporter通过Redis命令行获取指标
- mysql exporter通过读取数据库监控表获取MySQL的性能数据
PromQL
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持
matric固定格式: <metric name>{<label name>=<label value>, ...}
1 | node_memory_MemFree_bytes{instance="node02",job="node02"} |
监控名称查询:
1 | 如下查询了cpu的空闲和非空闲时的使用时间 |
范围查询:
s- 秒m- 分钟h- 小时d- 天w- 周y- 年
1 | pushgateway_http_requests_total{instance=~"pushgateway",method='get'}[1m] |
时间位移查询
1 | pushgateway_http_requests_total{instance=~"pushgateway",method='get'} offset 1d |
聚合查询
1 | 查询昨天1天内pushgeteway中get的请求总量之和 |
DownSample原理
前提是:数据的处理符合结合律,多个采样点的值的合并不会影响最终的计算结果。
原理: 降采样说白了就是降低数据的分辨率, 将一定时间间隔内的点,基于一定规则,聚合为一个或者一组值,从而达到降低采样点数,将少数据量,减轻数据查询的压力。比如: 30s采集周期,5min的时间间隔就是将6个点转化为1个点
- 时间间隔:经验值5min or 1h
- 5min: 当查询时间跨度在40h-240h之间
- 1h: 查询时间大于10天
- 聚合规则
- max:典型的max_over_time
- Min: min_over_time
- Sum: sum_over_time
- Count: count_over_time
- avg: 取时间间隔内点的平均值
- counter: 计算变化率,典型的有rate,increase
step duration区别

rate与irate区别
rate(v range-vector) 计算范围向量中时间序列的每秒平均增长率。单调性中断(例如由于目标重新启动而导致的计数器重置)会自动调整。此外,计算还会推断到时间范围的末尾,从而允许遗漏刮擦或刮擦周期与范围时间段的不完美对齐。duration的末尾的点减起始点
1 | value = end-start |
irate(v range-vector) 计算范围向量中时间序列的每秒瞬时增长率。这是基于最后两个数据点。单调性中断(例如由于目标重新启动而导致的计数器重置)会自动调整。duration中最后两个时间点斜率
1 | value = end1 - end2 |