前端/数据库/Spring/Java-2021春招准备
1、前端
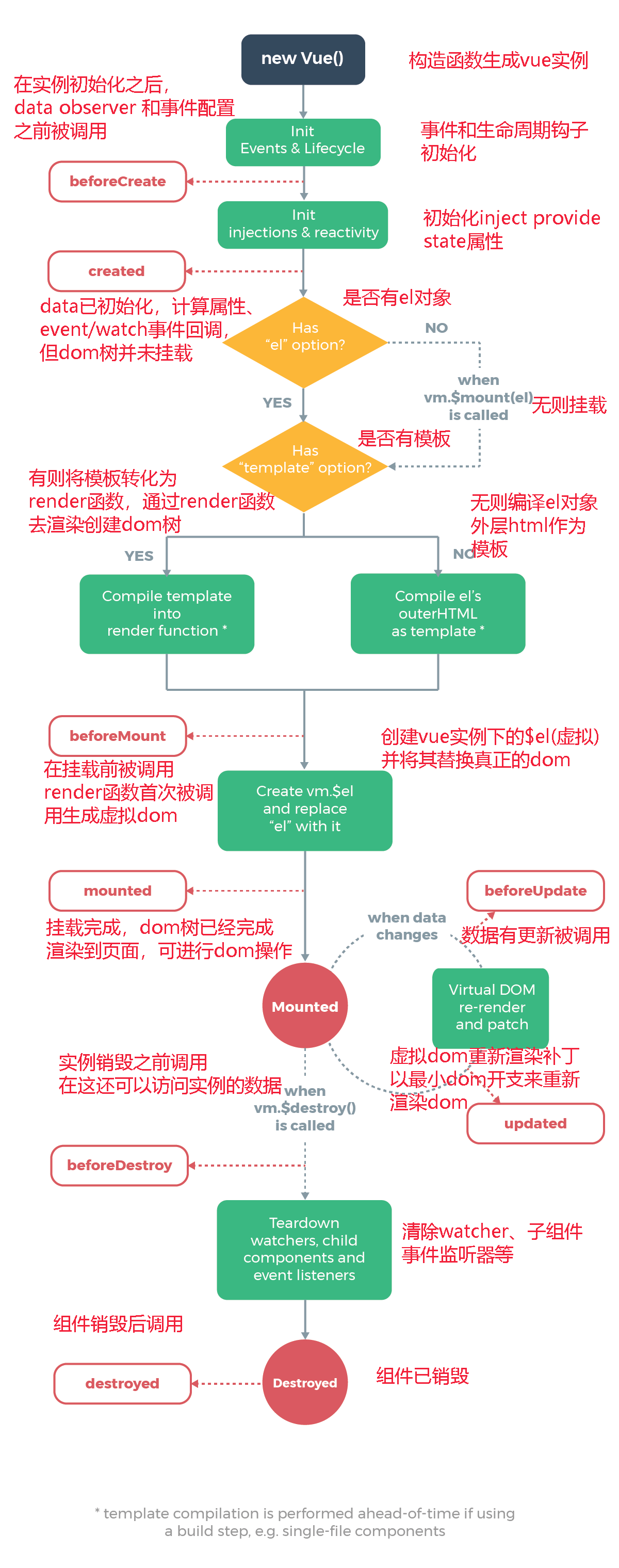
Vue生命周期
MVC/MVP/MVVM
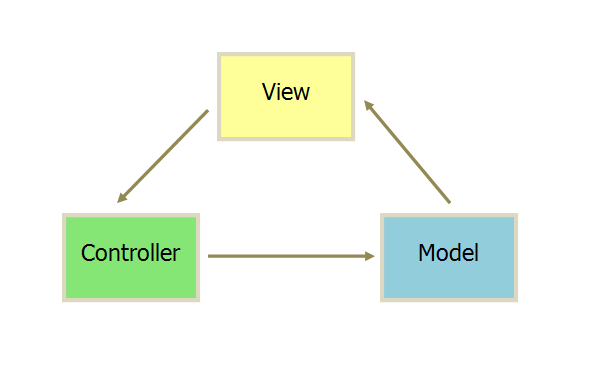
- View 传送指令到 Controller
- Controller 完成业务逻辑后,要求 Model 改变状态
- Model 将新的数据发送到 View,用户得到反馈
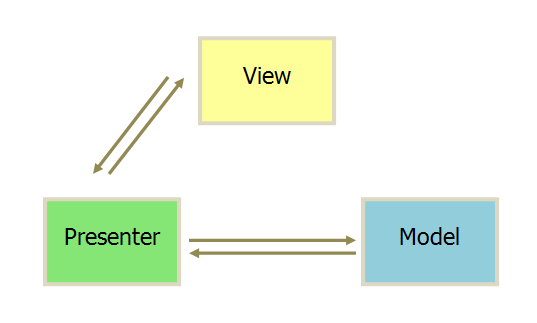
- 各部分之间的通信,都是双向的
- View 与 Model 不发生联系,都通过 Presenter 传递。
- View 非常薄,不部署任何业务逻辑,称为”被动视图”(Passive View),即没有任何主动性,而 Presenter非常厚,所有逻辑都部署在那里。
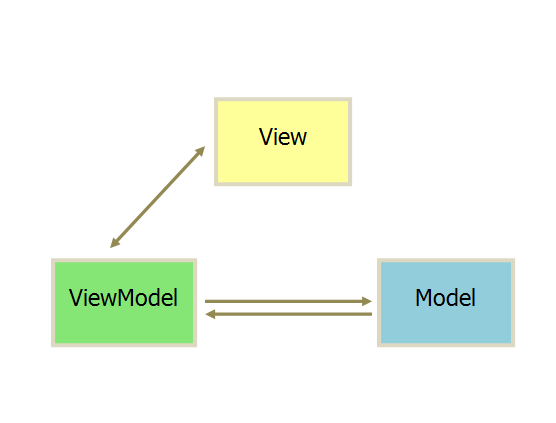
基本上与 MVP 模式完全一致,区别是双向绑定(data-binding):View的变动,自动反映在 ViewModel
2、数据库
事务
- 原子性( Atomicity ): 事务是数据库的逻辑工作单位,不可分割,事务中包含的各操作要么都做,要么都不做
- 一致性( Consistency ): 事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态
- 隔离性( Isolation ): 一个事务的执行不能其它事务干扰
- 持续性( Durability ): 也称永久性,指一个事务一旦提交,它对数据库中的数据的改变就应该是永久性的,不能回滚
索引:
索引可以加快数据库的检索速度,但是会降低新增、修改、删除操作的速度
类型
唯一索引:索引的每一个索引值只对应唯一的数据记录
主键索引:在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型
聚集索引:表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。 如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
实现方式
B+树:
- 为了尽量保持树的平衡,当然红黑树是二叉树,但B+树就不是二叉树了,B+树一般来说比较矮胖,而红黑树就比较瘦高了
- 如果经常需要同时对两个字段进行AND查询,那么使用两个单独索引不如建立一个复合索引,因为两个单独索引通常数据库只能使用其中一个,而使用复合索引因为索引本身就对应到两个字段上的,效率会有很大提高。
散列(Hash)索引:
- 通过散列函数来定位的一种索引,不过很少有单独使用散列索引的,反而是散列文件组织用的比较多
- 散列文件组织就是根据一个键通过散列计算把对应的记录都放到同一个桶中,这样的话相同的键值对应的记录就一定是放在同一个文件里了,也就减少了文件读取的次数,提高了效率。
位图索引:
- 位图索引是一种针对多个字段的简单查询设计一种特殊的索引,只适用于字段值固定并且值的种类很少的情况,比如性别,只能有男和女,或者级别,状态等等,并且只有在同时对多个这样的字段查询时才能体现出位图的优势
- 位图的基本思想就是对每一个条件都用0或者1来表示,如有5条记录,性别分别是男,女,男,男,女,那么如果使用位图索引就会建立两个位图,对应男的10110和对应女的01001,这样做有什么好处呢,就是如果同时对多个这种类型的字段进行and或or查询时,可以使用按位与和按位或来直接得到结果了
查看是否命中索引
用到explain这个命令来查看一个这些SQL语句的执行计划
数据库隔离级别:
事务并发可能出现的情况
- 脏读:一个事务读到了另一个未提交事务修改过的数据
- 不可重复读(Non-Repeatable Read):一个事务只能读到另一个已经提交的事务修改过的数据,并且其他事务每对该数据进行一次修改并提交后,该事务都能查询得到最新值。
- 幻读(Phantom):一个事务先根据某些条件查询出一些记录,之后另一个事务又向表中插入了符合这些条件的记录,原先的事务再次按照该条件查询时,能把另一个事务插入的记录也读出来

隔离级别
隔离级别比较:可串行化>可重复读>读已提交>读未提交
- 读未提交: 事务A可以读取到事务B修改过但未提交的数据
- 可能发生脏读、不可重复读和幻读问题
- 读已提交: 事务B只能在事务A修改过并且已提交后才能读取到事务B修改的数据
- 解决了脏读的问题,但可能发生不可重复读和幻读问题
- 可重复读: 在可重复读隔离级别下,事务B只能在事务A修改过数据并提交后,自己也提交事务后,才能读取到事务B修改的数据
- 解决了脏读和不可重复读的问题,但可能发生幻读问题
- 可串行化:
- 通过加锁实现(读锁和写锁)

乐观锁与悲观锁
乐观锁比较适用于读多写少的情况(多读场景)
悲观锁比较适用于写多读少的情况(多写场景)
悲观锁: 悲观锁中的共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程
乐观锁: 很乐观,每次去拿数据的时候都认为别人不会修改。所以不会上锁,但是如果想要更新数据,则会在更新前检查在读取至更新这段时间别人有没有修改过这个数据。如果修改过,则重新读取,再次尝试更新,循环上述步骤直到更新成功(当然也允许更新失败的线程放弃操作)
数据库两种引擎
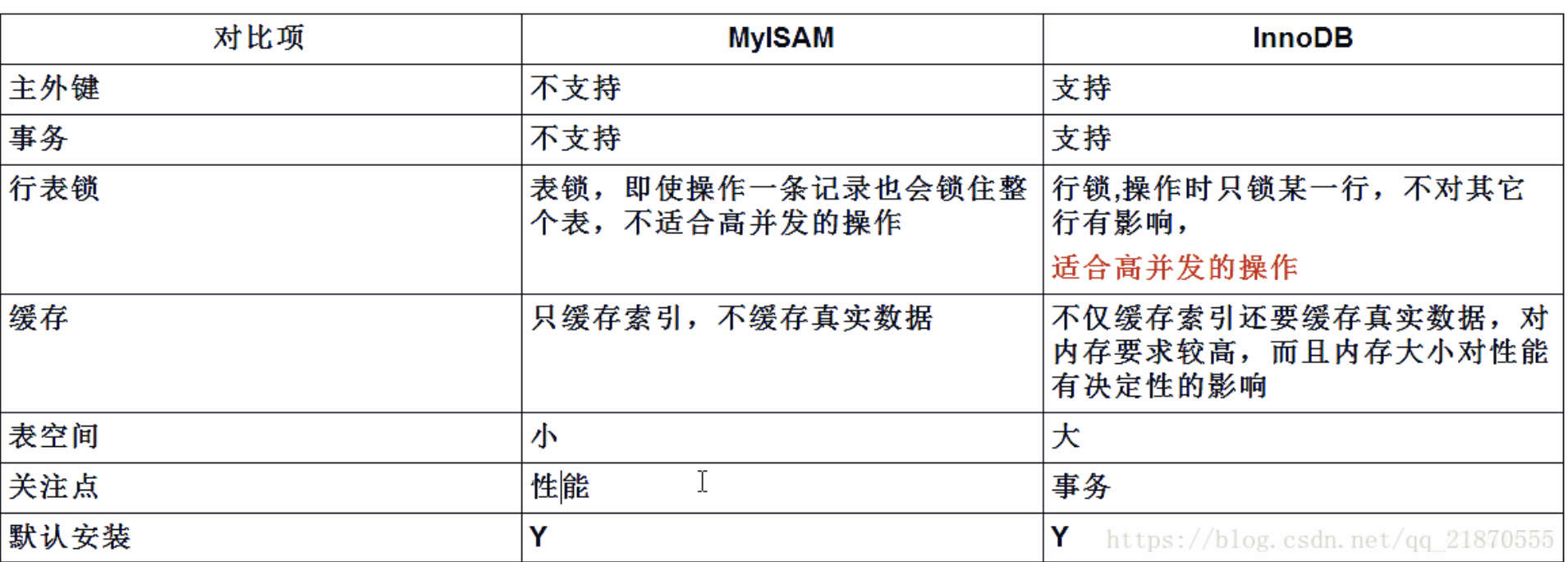
Innodb引擎
- Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别
- 该引擎提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。
- 该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当
SELECT COUNT(*) FROM TABLE时需要扫描全表。 - 由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
MyISAM引擎
- MyISAM是MySQL默认的引擎,但是它没有提供对数据库事务的支持,
- 不支持行级锁和外键,因此当
INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。 - MyISAM中存储了表的行数,
SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描 - 如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyISAM也是很好的选择。
主要区别
MyISAM是非事务安全的,而InnoDB是事务安全的
MyISAM锁的粒度是表级的,而InnoDB支持行级锁
MyISAM支持全文类型索引,而InnoDB不支持全文索引
MyISAM相对简单,效率上要优于InnoDB,小型应用可以考虑使用MyISAM
MyISAM表保存成文件形式,跨平台使用更加方便
选择
InnoDB
- 支持事务处理,支持外键,支持崩溃修复能力和并发控制
- 需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势
- 需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
MyISAM
- 插入数据快,空间和内存使用比较低
- 主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。
- 应用的完整性、并发性要求比较低,也可以使用
3、Spring
启动过程
- new了一个SpringApplication对象,使用SPI技术加载spring.factories文件中ApplicationContextInitializer、ApplicationListener 接口实例
- 调用SpringApplication.run() 方法
- 调用createApplicationContext()方法创建上下文对象,创建上下文对象同时会注册spring的核心组件类(ConfigurationClassPostProcessor 、AutowiredAnnotationBeanPostProcessor 等)
- 调用refreshContext() 方法启动Spring容器和内置的Servlet容器
Java程序启动过程
- 将java源码(.java文件)通过编译器(javac.exe)编译成JVM文件(.class文件)
- 将JVM文件通过java.exe执行,输出结果