Python篇-2021春招准备
1、迭代器与生成器
迭代器
python中,任意对象,只要定义了**__next__**方法,它就是一个迭代器。因此,python中的容器如列表、元组、字典、集合、字符串都可以用于创建迭代器。
for循环从列表[1,2,3]中取元素,这种遍历过程就被称作迭代
1 | # 列表是迭代器 |
如果你不想用for循环迭代呢?这时你可以:
- 先调用容器(以字符串为例)的iter()函数
- 再使用 next() 内置函数来调用 next() 方法
- 当元素用尽时,next() 将引发 StopIteration 异常
1 | s = 'abc' |
生成器
通过列表生成式,我们可以直接创建一个列表。
但是,受到内存限制,列表容量肯定是有限的。
而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?
这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器(Generator)。
生成器也是一种迭代器,但是你只能对其迭代一次。这是因为它们并没有把所有的值存在内存中,而是在运行时生成值。
使用了 yield 的函数被称为生成器(generator)
1 | def reverse(data): |
Send
- 如果使用send函数唤醒生成器,第一次调用send的时候,传入的值为None
- 一般情况下会使用next()唤醒第一次
1 | def MyGenerator(): |
2、is与==的区别
Python中对象包含的三个基本要素
- id(身份标识) is判断
- type(数据类型)
- value(值) ==判断
1 | x = y = [4,5,6] |
3、__init__与__new__的区别
- __new__用于初始化一个实例
- __init__用于实例化后调用的第一个方法
- __str__重载print方法
1 | class Person: |
实现自定义metaclass
1 | class PositiveInteger(int): |
单例模式
1 | class Singleton(object): |
4、垃圾回收机制(GC)
引用计数为主,分代回收为辅
(a) 引用计数: 每个对象维护一个ob_ref,用来记录当前对象被引用的次数
如下情况引用计数器+1:
- 对象被创建: a=14
- 对象被引用: b=a
- 对象被作为参数传递到函数中: func(a)
- 对象作为一个元素存储在容器中, list = {a, ‘a’, ‘b’, 2}
如下情况引用计数器-1:
- 对象的别名被显式销毁: del a
- 该对象的引用别名被赋予新的对象: a=26
- 一个对象离开作用阈,局部变量引用计数器-1
- 元素从容器中删除或容器被销毁
当计数器为0时被销毁
优点:
- 高效
- 无停顿、实时性
- 对象有确定生命周期
- 易于实现
缺点:
- 维护引用计数消耗资源
- 无法解决循环引用
1 | list1 = [] |
(b) 标记-清除: 基于追踪回收(tracing GC)
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象
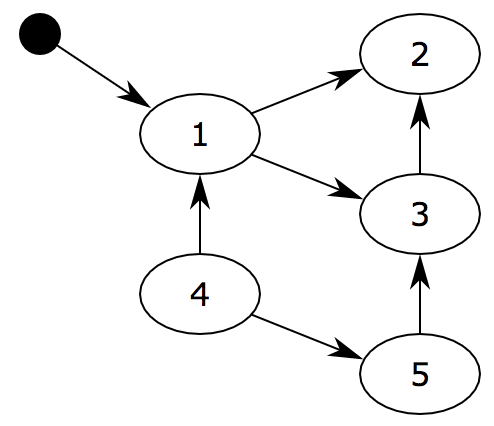
在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。
缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象
(c)分代回收:
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时或者超过一定的阈值,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
(d)过程:
- 分配内存
- 发现超过阈值了
- 触发垃圾回收
- 将所有可收集对象链表放到一起
- 遍历, 计算有效引用计数
- 分成 有效引用计数=0 和 有效引用计数 > 0 两个集合
- 大于0的, 放入到更老一代
- =0的, 执行回收
- 回收遍历容器内的各个元素, 减掉对应元素引用计数(破掉循环引用)
- 执行-1的逻辑, 若发现对象引用计数=0, 触发内存回收
- python底层内存管理机制回收内存
5、多线程
python3是假的多线程,它不是真真正正的并行,其实就是串行,只不过利用了cpu上下文的切换而已
只有获得GIL锁的线程才能真正在cpu上运行。所以,多线程在python中只能交替执行,即使100个线程跑在100核cpu上,也只能用到1核。
- 线程: 线程被称为轻量级进程,是最小执行单元,系统调度的单位。线程切换需要的资源一般,效率一般。
- 多线程: 在单个程序中同时运行多个线程完成不同的工作,称为多线程
- 并发:操作系统同时执行几个程序,这几个程序都由一个cpu处理,但在一个时刻点上只有一个程序在cpu上处理
- 并行:操作系统同时执行2个程序,但是有两个cpu,每个cpu处理一个程序,叫并行
- 串行: 是指的我们从事某项工作是一个步骤一个步骤去实施
1 | import threading |
Global Interpreter Lock(全局解释器锁GIL)
某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。适合IO密集型
用multiprocessing替代Thread,多核下,想做并行提升效率,比较通用的方法是使用多进程,能够有效提高执行效率
1 | import threading |
6、函数式编程
允许把函数本身作为参数传入另一个函数,还允许返回一个函数
- 变量可以指向函数
1 | func_abs = abs |
- 函数可以作为函数的参数
1 | def add(x, y, f): |
返回值为函数
闭包: 闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例,名称相同的变量在不同环境中代表的意义不同
匿名函数
lambda:
1 | # 冒号前面是参数,后面是返回值 |
- 装饰器: decorator就是一个返回函数的高阶函数
- 接收被装饰的函数作为参数
1 | # 装饰器无参数 |
7、常见的库
- datetime
- os
- random
- math
- sys
- pandas
- numpy
- matplotlib
Python动态创建类
1 | from com.twowater.hello import Hello |
在这里,需先了解下通过 type() 函数创建 class 对象的参数说明:
1、class 的名称,比如例子中的起名为 Hello
2、继承的父类集合,注意 Python 支持多重继承,如果只有一个父类,tuple 要使用单元素写法;例子中继承 object 类,因为是单元素的 tuple ,所以写成 (object,)
3、class 的方法名称与函数绑定;例子中将函数 printHello 绑定在方法名 hello 中
具体的模式如下:
1 | type(类名, 父类的元组(针对继承的情况,可以为空),包含属性的字典(名称和值)) |