Raft原理-2021年春招准备
- 分布式一致性算法: zookeeper
- 动画演示
1、复制状态机
一个分布式的复制状态机系统由多个复制单元组成,每个复制单元均是一个状态机,它的状态保存在一组状态变量中,状态机的变量只能通过外部命令来改变。
简单理解的话,可以想象成是一组服务器,每个服务器是一个状态机,服务器的运行状态只能通过一行行的命令来改变。每一个状态机存储一个包含一系列指令的日志,严格按照顺序逐条执行日志中的指令,如果所有的状态机都能按照相同的日志执行指令,那么它们最终将达到相同的状态。
在复制状态机模型下,只要保证了操作日志的一致性,我们就能保证该分布式系统状态的一致性
2、选举过程
基本概念
在Raft协议中,将时间分成了一些任意长度的时间片,称为term,term使用连续递增的编号的进行识别,每一个term都从新的选举开始,candidate们会努力争取称为leader。如下图所示:
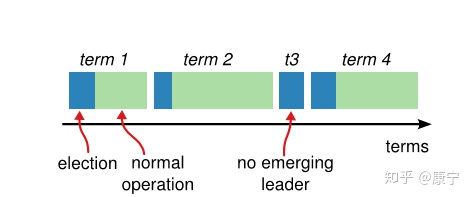
节点状态
- follower:所有结点都以follower的状态开始。如果没收到leader消息则会变成candidate状态
- candidate:会向其他结点“拉选票”,如果得到大部分的票则成为leader。这个过程就叫做Leader选举(Leader Election)
- leader:所有对系统的修改都会先经过leader。每个修改都会写一条日志(log entry)。leader收到修改请求后的过程如下,这个过程叫做日志复制(Log Replication):
- 复制日志到所有follower结点(replicate entry)
- 大部分结点响应时才提交日志
- 通知所有follower结点日志已提交
- 所有follower也提交日志
- 现在整个系统处于一致的状态
选举
当follower在选举超时时间(election timeout)内未收到leader的心跳消息(append entries),则变成candidate状态。为了避免选举冲突,这个超时时间是一个150~300ms之间的随机数。
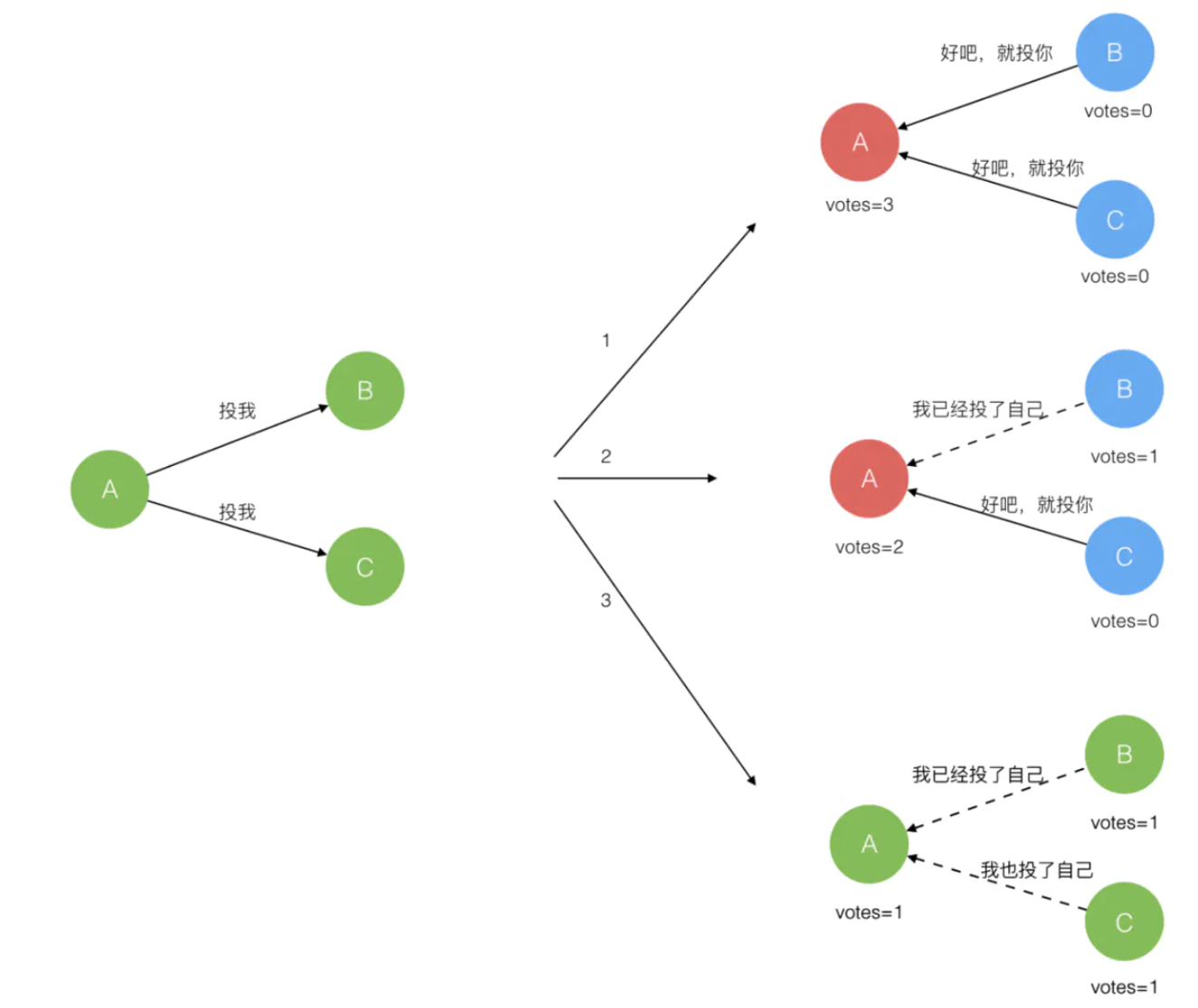
成为candidate的结点发起新的选举期(election term)去“拉选票”
重置自己的计时器,投自己一票,发送 Request Vote消息
如果接收结点在新term内没有投过票那它就会投给此candidate,并重置它自己的选举超时时间。
candidate拉到大部分选票就会成为leader,并定时发送心跳——Append Entries消息,去重置各个follower的计时器。当前Term会继续直到某个follower接收不到心跳并成为candidate。
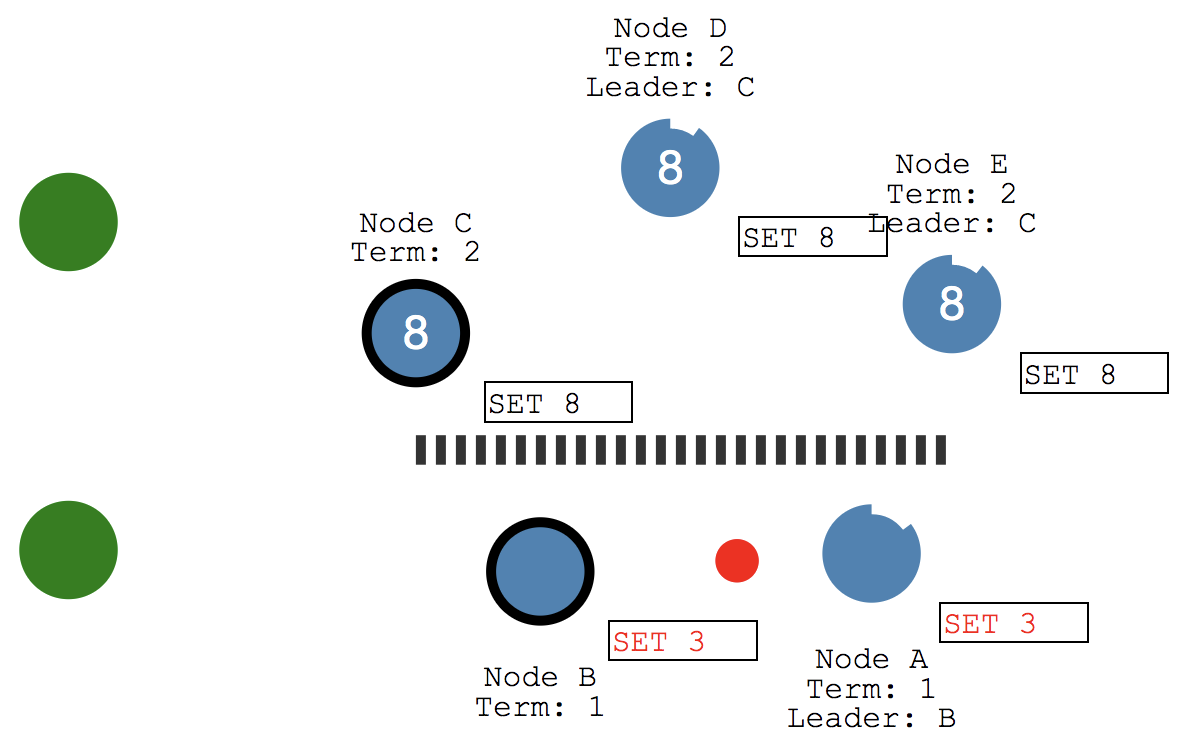
3、Log Replication(日志复制)
这是通过使用用于心跳的相同的附加条目消息来实现的。
- 客户端发送一条change到leader
- change记录到leader的日志中
- leader在下一个心跳中将change发给follwer(AppendEntries RPC用以复制命令)
- 一旦大多数follower承认一个条目,leader提交命令并将执行结果返回客户端
- leader将给client发送一条response
当存在多leader冲突时,所有的提交都会以最新的term的leader为主
4、日志压缩
随着日志大小的增长,会占用更多的内存空间,处理起来也会耗费更多的时间,对系统的可用性造成影响。
Snapshotting是最简单的压缩方法,系统的全部状态会写入一个snapshot保存起来,然后丢弃截止到snapshot时间点之前的所有日志。
每一个server都有自己的snapshot,它只保存当前状态,如上图中的当前状态为x=0,y=9,而last included index和last included term代表snapshot之前最新的命令,用于AppendEntries的状态检查。
虽然每一个server都保存有自己的snapshot,但是当follower严重落后于leader时,leader需要把自己的snapshot发送给follower加快同步,此时用到了一个新的RPC:InstallSnapshot RPC