大数据基础
温故知新
1、大数据的基本特征?
大数据技术:Hadoop和类Hadoop的分布式技术体系
- 数据规模巨大
- 数据类型多样
- 生成和处理速度极快
- 价值巨大但密度较低
2、Hadoop经历了几个发展阶段,各有什么特点?
- 前Hadoop时代
- Google发表了《Google File System》论文
- Google发表了《MapReduce》论文
- Apache Hadoop项目启动,并支持MapReduce与HDF独立发展
- Google发表《BigTable》论文
- Hadoop时代
- Hadoop成为Apache顶级项目
- Hadoop顶级项目Cloudera成立
- Cloudera发布Hadoop发行版CDH,并开源
- HDFS NameNode HA加入Hadoop主版本
3、大数据技术体系大致分为几层?每层包括哪些技术?

4、Apache Hadoop 项目包含哪些子项目?讲述一下他们的功能
- 分布式文件系统-HDFS
- 一次写入,多次读取
- 批处理计算框架-MapReduce
- 面向批处理的分布式计算框架
- 高性能计算框架-Spark
- 分布式资源管理系统-YARN
- 解决MapReduce1.X中的缺陷
- 容器技术-Docker
- 开源容器应用引擎
- 容器化集群操作系统-Kubernetes
- 开源容器化集群管理引擎
- Hadoop数据仓库&SQL引擎Hive
- 分布式NoSQL数据库-HBase
- 分布式搜索引擎-ElastisSearch
5、Spark包含哪些组件?简述一下他们的功能
- Spark Core:基础计算卡框架(批处理、交互式分析)
- Spark SQL:SQL引擎(海量结构化数据的高性能查询)
- Spark Streaming:实时流处理(微批)
- Spark Mlib:机器学习
- Spark GraphX:图计算
6、HDFS架构中包含哪些角色?各自承担什么功能?

- Active NameNode
- 活动Master管理节点
- 管理命名空间
- 管理元数据:文件位置、所有者、权限、数据块
- 管理Block副本(默认三个副本)
- Standby NameNode
- 热备份Master节点
- Active宕机后成为新的Active
- 同步元数据,周期性的下载edits日志,生成fsimage镜像检查点
- NameNode元数据文件
- 编辑edit日志文件:保存了最新的检查点
- fsimage:元数据检查点镜像文件
- DataNode
- Slave工作节点
- 存储Block和数据校验和
- 执行客户端发送
- Block数据块
- HDFS最小存储单元
- 文件写入HDFS会被切分成多个Block
- Block大小固定,默认为128M
- 默认情况下,每个Block有3个副本
- Client
- 将文件切分成Block
- 与NameNode交互,获取文件访问计划和相关元数据
- 与DataNode交互,读取或写入数据
- 管理HDFS
7、为什么HDFS不适合存储大量的小文件?
- HDFS不适合大量小文件的存储,因namenode将文件系统的元数据存放在内存中,因此存储的文件数目受限于 namenode的内存大小。HDFS中每个文件、目录、数据块占用150Bytes。如果存放的文件数目过多的话会占用很大的内存
- 放小文件与大文件占据的内存是相同的
- HDFS适用于高吞吐量,而不适合低时间延迟的访问。如果同时存入大量的小文件会花费很长的时间
8、Block副本放置的策略是什么?如何理解?
- 副本1:放在Client所在节点 -对于远程Client,系统会随机选择节点
- 副本2:放在不同的机架节点上
- 副本3:放在与第二个副本同一机架的不同节点上
- 副本N:随机选择
- 节点选择:同等条件下优先选择空闲节点

9、HDFS离开安全模式的条件是什么?
安全模式下HDFS只读
- Block上报率:DataNode上报的可用Block个数 / NameNode元数据记录的Block个数
- 当Block上报率 >= 阈值时,HDFS才能离开安全模式,默认阈值为0.999
- 不建议手动强制退出安全模式
10、HDFS是如何实现高可用的?
- Active NN与Standby NN的主备切换
- 利用QJM实现元数据高可用
- 只要保证Quorum(法定人数)数量的操作成功,就认为这是一次最终成功的操作
- QJM共享存储系统
- 部署奇数(2N+1)个JournalNode
- JournalNode负责存储edits编辑日志
- 写edits的时候,只要超过半数(N+1)的 JournalNode返回成功,就代表本次写入成功
- 最多可容忍N个JournalNode宕机
- 基于Paxos算法实现
- 利用ZooKeeper实现Active节点选举


分布式资源管理系统YARN
1、YARN简介
1、作业(job)分解后是task,运行task需要资源
2、任务的调度,分析哪些任务是并行的串行的
1.1 MapReduce的缺陷(Hadoop 1.X)
- 身兼两个职能:计算架构+资源管理系统
- Job Tracker
- 既做资源管理,又做任务调度
- 任务太重,开销过大
- 存在单点故障
- Task Tracker
- Job Tracker

2、YARN原理
2.1 系统架构
计算跟着数据走,用于计算的程序分配到YARN节点上,YARN找到DataNode的数据
- ResourceManager
- 知道哪儿有DataNode
- 集群资源的统一管理和分配
- 资源管理,账本,目录
- 将资源分配给应用(ApplicationMaster)
- NodeManager
- 管理本机的资源即管理container(最小资源单位)
- container资源的生命周期
- ApplicationMaster
- 管理作业,将作业分解为task,返回给RM
- 任务管理
- 特殊的管理进程,YARN提供MapReduce的ApplicationMaster实现
- 支持MapReduce

工作机制:

2.2 高可用
- ResourceManager

YARN调度策略
分配container
- FIFO调度器(先进先出)
- 容器调度器
- 核心思想:提前做预算,在预算指导下分享集群资源
- 公平调度器:见面分一半
YARN运维与监控
- CTRL^C不能终止任务,只是停止其在控制台的信息输出,任务仍在集群中运行
分布式计算框架
MapReduce 简介
1.1 MR简介
- 2004年10月 Google发表了MR论文
- MapReduce被分为Map(映射)阶段和Reduce(化简)阶段
- 分而治之,并行计算
- 移动计算,并非移动移动
- MapReduce是图纸,YARN是建造者
- 场景:
- 网站的PV、UV统计
- 搜索引擎构建索引,不需要时间,对时间要求低,不容易出错
- 海量数据查询
- 不适用场景:
- OLAP
- 毫秒级、秒级查询
1.2 MR原理
Mapping 输出3份,Reducing输入4份,不对等,所以shuffling(洗牌),shuffling并不存在是虚拟的
实践中,Map多,reduce少

- Job&Task
- Split
- 逻辑概念,包含元数据信息,如数据的起始位置、长度、所在的节点等
- Split决定Map数量
- Split大小默认等于Block的大小
- Map(映射)
- key-value的形式<a, 1>
- Reduce(化简)
- 先写Buffer,落盘(内存,硬盘)
- Shuffle(混洗)优化的关键
- Hash 取模–将一个数据集均匀随机打散
- Key做Hash%reduce的数量
- Hash 取模–将一个数据集均匀随机打散



Spark
1.1 Spark简介
- MapReduce存在缺陷
- 计算框架种类多,选型难,学习成本高
- 统一计算框架,简化技术选型
- 统一的框架下,实现批处理、流处理、交互式计算、机器学习
- 实时,对准确率要求相对较低,主要在内存中,实在躲不过去才落盘(放到磁盘)
- 大规模分布式通用计算引擎
- Spark Core
- Spark SQL
- Spark Streaming
- Spark Mlib
- Spar图计算
1.2 Spark原理:编程模型
- RDD(弹性分布式数据集,大的表,分布式)
- 分布式
- 只读
- 弹性,不怕坏,转换操作(将坏的Partition重算)

- RDD操作:
- Transformation(转换)
- 从无到有生成RDD
- 从已有的RDD生成新的RDD
- 惰性计算,只记录关系,最后落盘的时候计算
- Action(动作)
- 算完了,落盘了
- Transformation(转换)
- RDD依赖:
- 窄依赖(推荐)
- 父RDD的分区,最多被子RDD的和一个分区使用
- 父分区与子分区个数对等
- 宽依赖(尽可能少用)
- 子RDD严重依赖父RDD的所有分区
- 分区就要排序,排序就要落盘,落盘就要shuffing,速度就慢了
- 父分区与子分区个数对等
- 子RDD严重依赖父RDD的所有分区
- 窄依赖(推荐)
 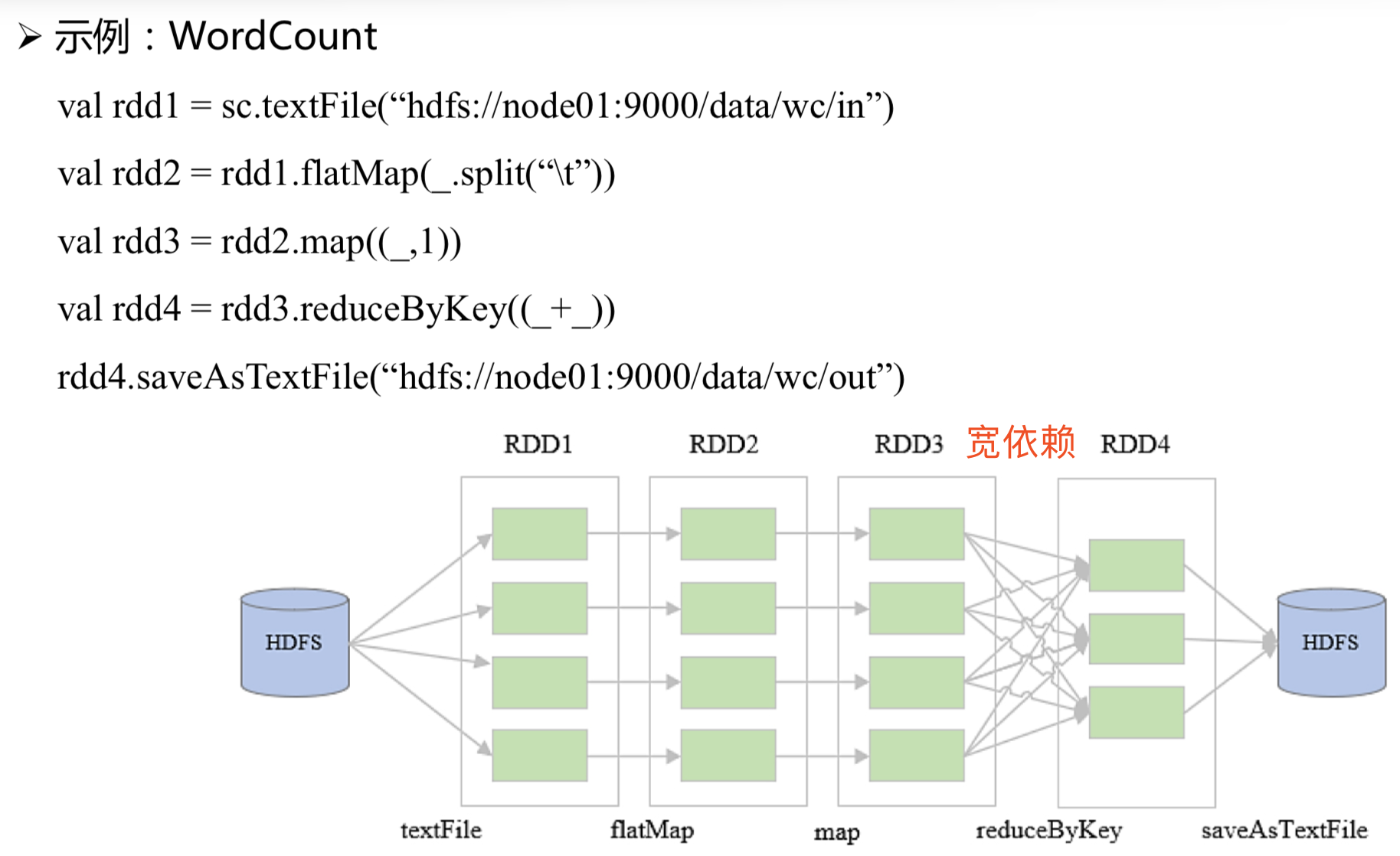

1.3 Spark原理:运行模式
- 抽象模式
- Driver
- 一个Spark程序有一个Driver,一个Driver创建一个SparkContext,程序的main函数运行在Driver中
- 负责解析Spark程序、划分Stage、调度任务到Executor上执行
- SparkContext
- 负责加载配置信息,初始化运行环境,创建DAGScheduler和TaskScheduler
- Executor
- 负责执行Driver分发的任务,一个节点可以启动多个Executor,每个Executor通过多线程运行多个任务
- Task -Spark运行的基本单位,一个Task负责处理若干RDD分区的计算逻辑
- Driver

- Local模式
- Standalone模式
- YARN模式
1.4 Spark原理:运行过程
DAG:生成有向无环图

- 生成逻辑计划

- 生成物理计划

- 任务调度与执行

分布式ETL工具Sqoop
将关系数据库里面的内容进行迁移
1. Sqoop简介
1.1 Sqoop是什么
- Hadoop与关系数据库的主要的迁移工具
1.2 Sqoop版本

2.Sqoop原理
2.1数据导入

2.2数据导出

3.Sqoop使用
分布式数据采集工具Flume
1、Flume简介
1.1 什么是Flume
- Flume是一个分布式海量数据采集、聚合和传输系统
- 基于事件的海量数据采集
- 数据流模型:Source–>Channel–>Sink
- 事务机制:支持重读重写,保证消息传递的可靠性
2、Flume原理
2.1 基本概念
- Event:事件,最小数据传输单元,由Header和Body组成
- Agent:代理,JVM进程,最小运行单元,由Source、Channel、Sink三个基本组件构成,负责将外部数据源产生的数据以Event的形式传输到目的地
- Source:负责对接各种外部数据源,将采集到的数据封装成Event,然后写入Channel
- Channel:Event暂存容器,负责保存Source发送的Event,直至被Sink成功读取
- Sink:负责从Channel读取Event,然后将其写入外部存储,或传输给下一阶段的Agent
- 映射关系:1个Source 多个Channel,1个Channel 多个Sink,1个Sink 1个Channel

2.2 Flume组件
- Source组件
- Channel组件
- Sink组件




2.3 Flume数据流
2.4Flume架构
- 单层架构

- 多层架构

3、Flume使用
分布式消息队列KaFka
1、Kafka简介
1.1 什么是Kafka
- 基于发布/订阅的分布式消息系统
- 消息持久化:采用时间复杂度 的磁盘存储结构,即使级以上数据也能保证常数时间的访问速度
- 高吞吐: 即使在廉价的商用机器上,也能达到单机每秒10万条消息的传输
- 高容错:多分区多副本 • 易扩展:新增机器,集群无需停机,自动感知
- 同时支持离线、实时数据处理
1.2 应用场景
- 异步通信
- 应用解耦
- 峰值处理
2、Kafka原理
2.1 基本概念
- Broker(代理)
- Kafka的一个实例或节点,一个或多个Broker组成一个Kafka集群
- Topic(主题)
- Topic是Kafka中同一类数据的集合,相当于数据库中的表
- Producer将同一类数据写入同一个Topic,Consumer从同一个Topic中读取同类数据
- Topic是逻辑概念,用户只需指定Topic就可以生产或消费数据,不必关心数据存于何处
- Partition(分区)
- 分区是一个有序的、不可修改的消息队列,分区内消息有序存储
- 一个Topic可分为多个分区,相当于把一个数据集分成多份,分别存储不同的分区中
- Parition是物理概念,每个分区对应一个文件夹,其中存储分区的数据和索引文件
- Replication(副本)
- 一个分区可以设置多个副本,副本存储在不同的Broker中
- Producer
- Consumer
- Consumer Group(CG 消费组)
- 一条消息可以发送给多个不同的CG,一个CG中只能有一个Consumer读取该消息
- Zookeeper
2.2 工作机制
- 消息在Broker中按Topic(主题)进行分类,相当于为每个消息打个标签
- 一个Topic可划分为多个Partition(分区)
- 每个Partition可以有多个Replication(副本)
- 消息存储在Broker的某一Topic的某一Partition中,同时存在多个副本

分区分桶要考
Search
2、Search原理
2.1 数学模型
index
type(分类)
文档
字段
映射(Mapping)
- json的格式
2.2 分词与索引
- 分词
- 倒排索引
2.3 系统架构
- 节点和集群
- 节点:一个ElasticSearch实例
- 集群由一个或多个拥有相同claster.name配置的节点组成
- 主节点
- 负责管理集群内的所有变更
- 整个集群所有的节点,都有可能被选为主节点
- 配置一般
- 数据节点
- 开销很大
- 负责存储数据
- 硬件配置比较高
- 客户端节点
- 放了一张路由表
- 负责路由转发请求
- 分片
- Search的数据存储单元,数据的容器,Document(文档)存储在分片里面
HyperBase
1、HyperBase 简介
1.1 什么是HyperBase
- 概念
- 高可靠、高性能、高并发、可伸缩、实时读写、面向列的分布式NewSql数据库
- 基于HBase实现
- 四维表
- NewSql数据库
- 列式存储
- 适合放半结构化数据(xml,稀疏性)
- Key-Value数据库
- HDFS为文件存储系统

- 特点:
- 海量数据存储
- 高并发的简单查询
- 线性扩展
- 高并发、高可用
- 实时随机读写
- 数据的强一致性
- 海量数据存储
2、HyperBase原理
2.1 数据模型

rowkey:
- 根据字典排序
列族:BasicInfo、CourseInfo
- 有限
- 下面的列无限(name、age、telephone)(course、score)
name:列限定符
- 列族:列限定符—>列
单元格
- 由rowkey+列族+列限定符
timestamp:时间戳、数据的版本号;如:电话号码可以有多个,时间戳不同
key-value
- SF|
aS re
大数据基础
https://zhangfuli.github.io/2021/02/03/大数据基础/