1
2
3
4
5
6
7
8
| import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
|
1
2
3
4
5
| features = pd.read_csv('temps.csv')
features.head()
|
|
year |
month |
day |
week |
temp_2 |
temp_1 |
average |
actual |
friend |
| 0 |
2016 |
1 |
1 |
Fri |
45 |
45 |
45.6 |
45 |
29 |
| 1 |
2016 |
1 |
2 |
Sat |
44 |
45 |
45.7 |
44 |
61 |
| 2 |
2016 |
1 |
3 |
Sun |
45 |
44 |
45.8 |
41 |
56 |
| 3 |
2016 |
1 |
4 |
Mon |
44 |
41 |
45.9 |
40 |
53 |
| 4 |
2016 |
1 |
5 |
Tues |
41 |
40 |
46.0 |
44 |
41 |
(348, 9)
1
2
3
4
5
6
7
8
9
|
import datetime
years = features['year']
months = features['month']
days = features['day']
dates = [str(int(year)) + "-" + str((int(month))) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
|
[datetime.datetime(2016, 1, 1, 0, 0),
datetime.datetime(2016, 1, 2, 0, 0),
datetime.datetime(2016, 1, 3, 0, 0),
datetime.datetime(2016, 1, 4, 0, 0),
datetime.datetime(2016, 1, 5, 0, 0)]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
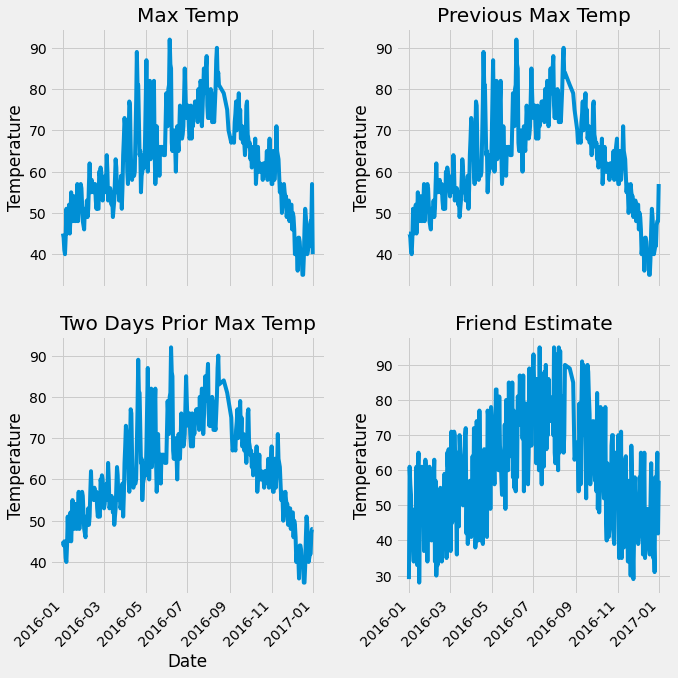
plt.style.use('fivethirtyeight')
fig, ((ax1,ax2),(ax3,ax4)) = plt.subplots(nrows=2,ncols=2,figsize=(10,10))
fig.autofmt_xdate(rotation = 45)
ax1.plot(dates, features['actual'])
ax1.set_xlabel('')
ax1.set_ylabel('Temperature')
ax1.set_title('Max Temp')
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel('')
ax2.set_ylabel('Temperature')
ax2.set_title('Previous Max Temp')
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date')
ax3.set_ylabel('Temperature')
ax3.set_title('Two Days Prior Max Temp')
ax4.plot(dates, features['friend'])
ax4.set_xlabel('')
ax4.set_ylabel('Temperature')
ax4.set_title('Friend Estimate')
plt.tight_layout(pad = 2)
|
1
2
3
|
features = pd.get_dummies(features)
features.head(5)
|
|
year |
month |
day |
temp_2 |
temp_1 |
average |
actual |
friend |
week_Fri |
week_Mon |
week_Sat |
week_Sun |
week_Thurs |
week_Tues |
week_Wed |
| 0 |
2016 |
1 |
1 |
45 |
45 |
45.6 |
45 |
29 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1 |
2016 |
1 |
2 |
44 |
45 |
45.7 |
44 |
61 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
| 2 |
2016 |
1 |
3 |
45 |
44 |
45.8 |
41 |
56 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
| 3 |
2016 |
1 |
4 |
44 |
41 |
45.9 |
40 |
53 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
| 4 |
2016 |
1 |
5 |
41 |
40 |
46.0 |
44 |
41 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1
2
3
4
5
6
7
8
9
10
11
|
labels = np.array(features['actual'])
features = features.drop('actual', axis = 1)
feature_list = list(features.columns)
features = np.array(features)
print(features.shape)
|
(348, 14)
1
2
3
| from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
input_features[0]
|
array([ 0. , -1.5678393 , -1.65682171, -1.48452388, -1.49443549,
-1.3470703 , -1.98891668, 2.44131112, -0.40482045, -0.40961596,
-0.40482045, -0.40482045, -0.41913682, -0.40482045])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
x = torch.tensor(input_features, dtype=float)
y = torch.tensor(labels, dtype = float)
weights = torch.randn((14,128), dtype=float, requires_grad = True)
biases = torch.randn(128, dtype=float, requires_grad = True)
weights2 = torch.randn((128,1), dtype=float, requires_grad = True)
biases2 = torch.randn(1, dtype=float, requires_grad = True)
learning_rate = 0.001
losses = []
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
for i in range(1000):
hidden = x.mm(weights) + biases
hidden = torch.relu(hidden)
predictions = hidden.mm(weights2) + biases2
loss = torch.mean((predictions - y)**2)
losses.append(loss.data.numpy())
if i %100 == 0:
print('loss: ', loss)
loss.backward()
weights.data.add_(- learning_rate * weights.grad.data)
biases.data.add_(- learning_rate * biases.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases.data.add_(- learning_rate * biases2.grad.data)
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
|
loss: tensor(2628.1660, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(155.1873, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(146.8026, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(144.0431, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(142.7121, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(141.9236, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(141.3944, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(141.0007, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(140.7019, dtype=torch.float64, grad_fn=<MeanBackward0>)
loss: tensor(140.4667, dtype=torch.float64, grad_fn=<MeanBackward0>)
1
2
3
4
5
6
7
8
9
10
11
12
|
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(), lr=0.001)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| losses = []
for i in range(1000):
batch_loss = []
for start in range(0, len(input_features), batch_size):
end = start + batch_size if start + batch_size < len(input_features) else len(input_features)
xx = torch.tensor(input_features[start:end], dtype=torch.float, requires_grad = True)
yy = torch.tensor(labels[start:end], dtype=torch.float, requires_grad = True)
prediction = my_nn(xx)
loss = cost(prediction, yy)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
batch_loss.append(loss.data.numpy())
if i % 100 == 0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
|
0 3880.0461
100 38.13609
200 35.70337
300 35.309303
400 35.13356
500 34.999176
600 34.880596
700 34.76389
800 34.643845
900 34.51949
1
2
3
|
x = torch.tensor(input_features, dtype=torch.float)
predict = my_nn(x).data.numpy()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predict.reshape(-1)})
|
1
2
3
4
5
6
7
8
9
10
11
|
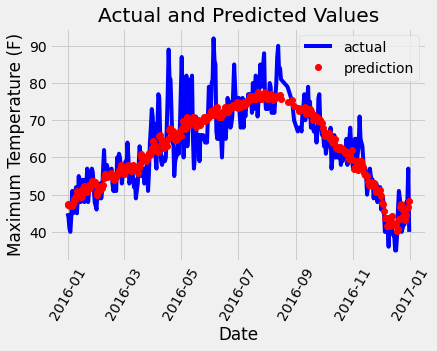
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = '60');
plt.legend()
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');
|